第1章:Kubernetes核心概念
-
Kubernetes是Google在2014年开源的一个容器集群管理系统,Kubernetes简称K8S。
-
Kubernetes用于容器化应用程序的部署,扩展和管理,目标是让部署容器化应用简单高效。
1.1 Kubernetes集群架构与组件
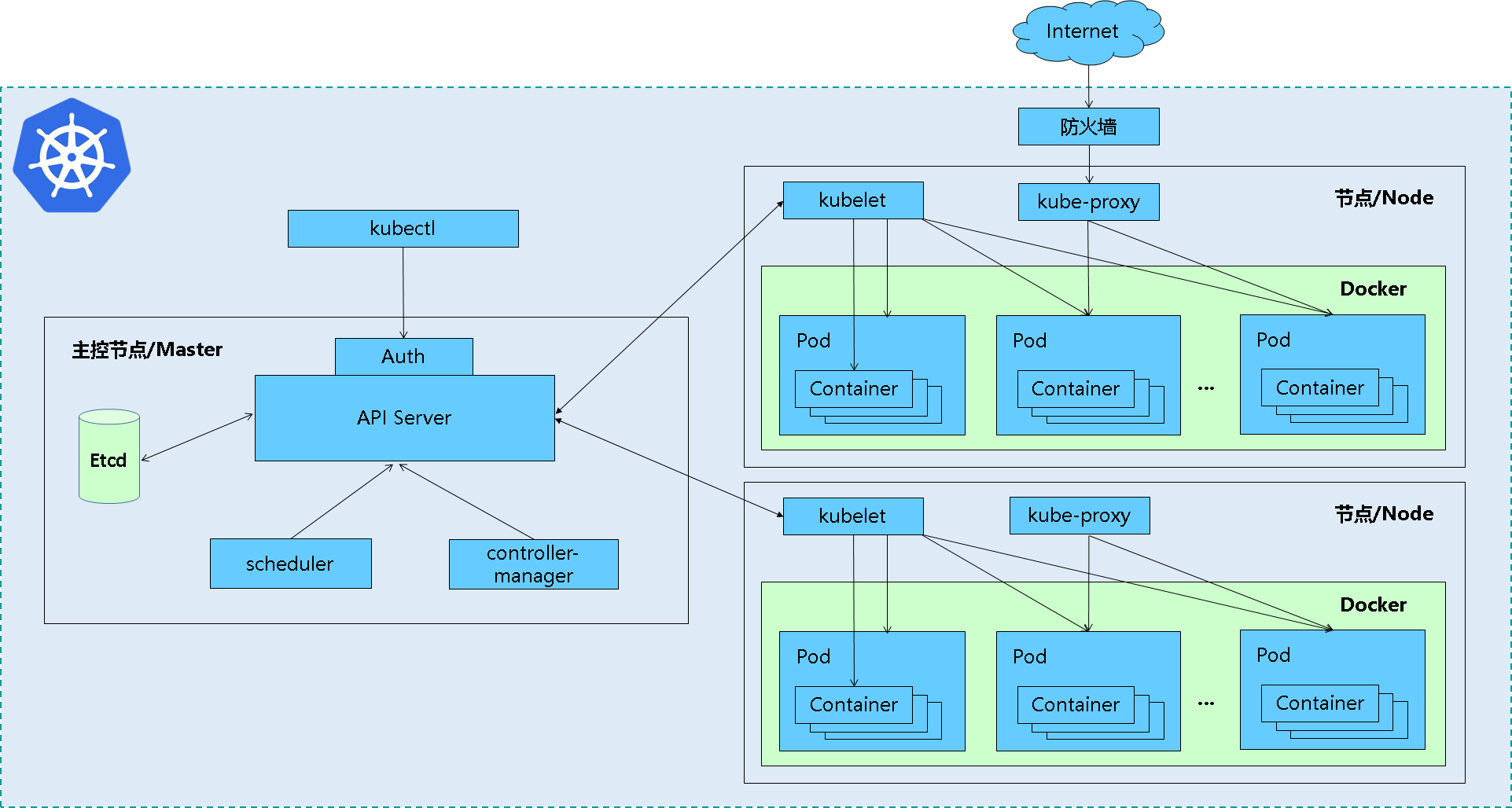
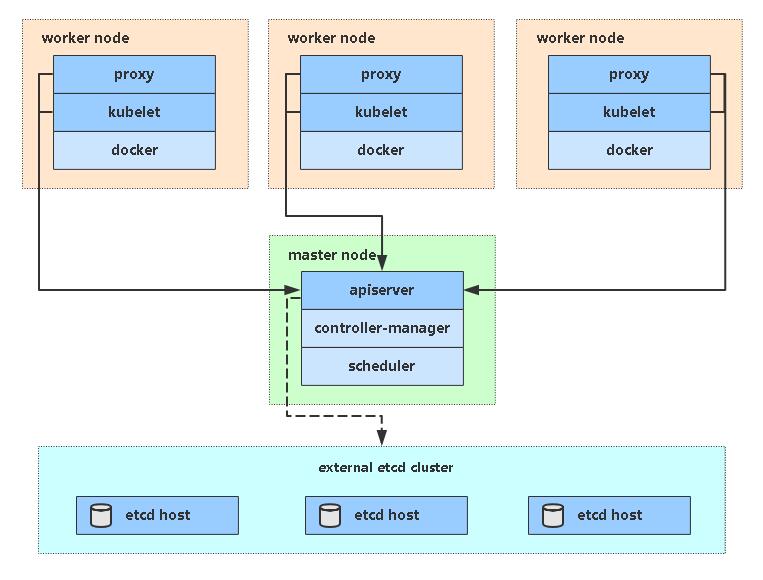
Master角色
- kube-apiserver
Kubernetes API,集群的统一入口,各组件协调者,以RESTful API提供接口服务,所有对象资源的增删改查和监听操作都交给APIServer处理后再提交给Etcd存储。
- kube-controller-manager
处理集群中常规后台任务,一个资源对应一个控制器,而ControllerManager就是负责管理这些控制器的。
- kube-scheduler
根据调度算法为新创建的Pod选择一个Node节点,可以任意部署,可以部署在同一个节点上,也可以部署在不同的节点上。
- etcd
分布式键值存储系统。用于保存集群状态数据,比如Pod、Service等对象信息。
Worker Node角色
- kubelet
kubelet是Master在Node节点上的Agent,管理本机运行容器的生命周期,比如创建容器、Pod挂载数据卷、下载secret、获取容器和节点状态等工作。kubelet将每个Pod转换成一组容器。
- kube-proxy
在Node节点上实现Pod网络代理,维护网络规则和四层负载均衡工作。
- docker或rocket
容器引擎,运行容器。
1.2 Kubernetes基本概念
Pod
- 最小部署单元
- 一组容器的集合
- 一个Pod中的容器共享网络命名空间
- Pod是短暂的
Controllers
- Deployment : 无状态应用部署
- StatefulSet : 有状态应用部署
- DaemonSet : 确保所有Node运行同一个Pod
- Job : 一次性任务
- Cronjob : 定时任务
控制器是更高级层次对象,用于部署和管理Pod。
Service
-
防止Pod失联
-
定义一组Pod的访问策略
Label : 标签,附加到某个资源上,用于关联对象、查询和筛选
Namespaces : 命名空间,将对象逻辑上隔离
第2章:快速部署一个Kubernetes集群
kubeadm是官方社区推出的一个用于快速部署kubernetes集群的工具。
这个工具能通过两条指令完成一个kubernetes集群的部署:
# 创建一个 Master 节点
$ kubeadm init
# 将一个 Node 节点加入到当前集群中
$ kubeadm join <Master节点的IP和端口 >
第3章:kubectl命令行管理工具
kubectl --help 查看帮助信息
kubectl create --help 查看create命令帮助信息
| 命令 | 描述 |
|---|---|
| create | 通过文件名或标准输入创建资源 |
| expose | 将一个资源公开为一个新的Service |
| run | 在集群中运行一个特定的镜像 |
| set | 在对象上设置特定的功能 |
| get | 显示一个或多个资源 |
| explain | 文档参考资料 |
| edit | 使用默认的编辑器编辑一个资源。 |
| delete | 通过文件名、标准输入、资源名称或标签选择器来删除资源。 |
| rollout | 管理资源的发布 |
| rolling-update | 对给定的复制控制器滚动更新 |
| scale | 扩容或缩容Pod数量,Deployment、ReplicaSet、RC或Job |
| autoscale | 创建一个自动选择扩容或缩容并设置Pod数量 |
| certificate | 修改证书资源 |
| cluster-info | 显示集群信息 |
| top | 显示资源(CPU/Memory/Storage)使用。需要Heapster运行 |
| cordon | 标记节点不可调度 |
| uncordon | 标记节点可调度 |
| drain | 驱逐节点上的应用,准备下线维护 |
| taint | 修改节点taint标记 |
| describe | 显示特定资源或资源组的详细信息 |
| logs | 在一个Pod中打印一个容器日志。如果Pod只有一个容器,容器名称是可选的 |
| attach | 附加到一个运行的容器 |
| exec | 执行命令到容器 |
| port-forward | 转发一个或多个本地端口到一个pod |
| proxy | 运行一个proxy到Kubernetes API server |
| cp | 拷贝文件或目录到容器中 |
| auth | 检查授权 |
| apply | 通过文件名或标准输入对资源应用配置 |
| patch | 使用补丁修改、更新资源的字段 |
| replace | 通过文件名或标准输入替换一个资源 |
| convert | 不同的API版本之间转换配置文件 |
| label | 更新资源上的标签 |
| annotate | 更新资源上的注释 |
| completion | 用于实现kubectl工具自动补全 |
| api-versions | 打印受支持的API版本 |
| config | 修改kubeconfig文件(用于访问API,比如配置认证信息) |
| help | 所有命令帮助 |
| plugin | 运行一个命令行插件 |
| version | 打印客户端和服务版本信息 |
使用kubectl管理应用生命周期
1、创建
kubectl create deployment web --image=lizhenliang/java-demo
kubectl get deploy,pods
2、发布
kubectl expose deployment web --port=80 --type=NodePort --target-port=80 --name=web
kubectl get service
3、升级
kubectl set image deployment/web nginx=nginx:1.15
kubectl rollout status deployment/nginx-deployment # 查看升级状态
4、回滚
kubectl rollout history deployment/web # 查看发布记录
kubectl rollout undo deployment/web # 回滚最新版本
kubectl rollout undo deployment/web --revision=2 # 回滚指定版本
5、删除
kubectl delete deploy/web
kubectl delete svc/web
第4章:资源编排(YAML)
4.1 编写YAML注意事项
YAML 是一种简洁的非标记语言。
语法格式:
-
缩进表示层级关系
-
不支持制表符“tab”缩进,使用空格缩进
-
通常开头缩进 2 个空格
-
字符后缩进 1 个空格,如冒号、逗号等
-
“---” 表示YAML格式,一个文件的开始
-
“#”注释
4.2 YAML内容解析
在K8S部署一个应用的YAML内容大致分为两部分:
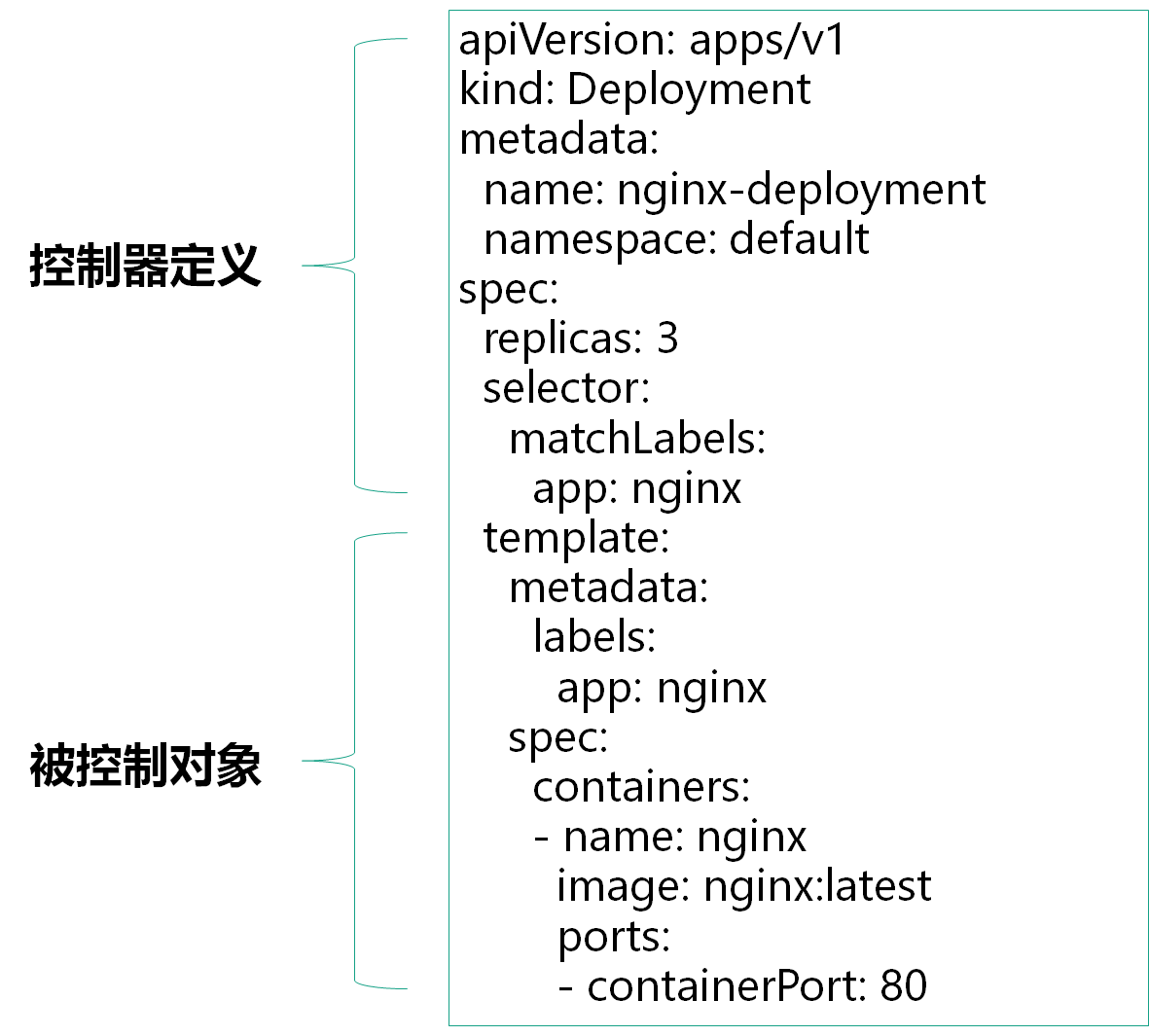
控制器定义:定义控制器属性
被控制对象:Pod模板,定义容器属性
具体字段意义:
| apiVersion | API版本 |
|---|---|
| kind | 资源类型 |
| metadata | 资源元数据 |
| spec | 资源规格 |
| replicas | 副本数量 |
| selector | 标签选择器 |
| template | Pod模板 |
| metadata | Pod元数据 |
| spec | Pod规格 |
| containers | 容器配置 |
第5章:深入理解Pod对象
Pod是最小的部署单元,也是后面经常配置的地方,本章节带你熟悉Pod中常见资源配置及参数。
也就是YAML这部分:
...
template:
metadata:
labels:
app: web
spec:
containers:
- image: lizhenliang/java-demo:latest
imagePullPolicy: Always
name: java
5.1 Pod介绍
-
最小部署单元
-
一组容器的集合
-
一个Pod中的容器共享网络命名空间
-
Pod是短暂的
5.2 Pod存在的意义
Pod为亲密性应用而存在。
亲密性应用场景:
-
两个应用之间发生文件交互
-
两个应用需要通过127.0.0.1或者socket通信
-
两个应用需要发生频繁的调用
5.3 Pod实现机制与设计模式
Pod本身是一个逻辑概念,没有具体存在,那究竟是怎么实现的呢?
众所周知,容器之间是通过Namespace隔离的,Pod要想解决上述应用场景,那么就要让Pod里的容器之间高效共享。
具体分为两个部分:网络和存储
- 共享网络
kubernetes的解法是这样的:会在每个Pod里先启动一个infra container小容器,然后让其他的容器连接进来这个网络命名空间,然后其他容器看到的网络试图就完全一样了,即网络设备、IP地址、Mac地址等,这就是解决网络共享问题。在Pod的IP地址就是infra container的IP地址。
- 共享存储
比如有两个容器,一个是nginx,另一个是普通的容器,普通容器要想访问nginx里的文件,就需要nginx容器将共享目录通过volume挂载出来,然后让普通容器挂载的这个volume,最后大家看到这个共享目录的内容一样。
例如:
# pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: my-pod
spec:
containers:
- name: write
image: centos
command: ["bash","-c","for i in {1..100};do echo $i >> /data/hello;sleep 1;done"]
volumeMounts:
- name: data
mountPath: /data
- name: read
image: centos
command: ["bash","-c","tail -f /data/hello"]
volumeMounts:
- name: data
mountPath: /data
volumes:
- name: data
emptyDir: {}
上述示例中有两个容器,write容器负责提供数据,read消费数据,通过数据卷将写入数据的目录和读取数据的目录都放到了该卷中,这样每个容器都能看到该目录。
验证:
kubectl apply -f pod.yaml
kubectl logs my-pod -c read -f
在Pod中容器分为以下几个类型:
-
Infrastructure Container:基础容器,维护整个Pod网络空间,对用户不可见
-
InitContainers:初始化容器,先于业务容器开始执行,一般用于业务容器的初始化工作
-
Containers:业务容器,具体跑应用程序的镜像
5.4 镜像拉取策略
apiVersion: v1
kind: Pod
metadata:
name: my-pod
spec:
containers:
- name: java
image: lizhenliang/java-demo
imagePullPolicy: IfNotPresent
imagePullPolicy 字段有三个可选值:
-
IfNotPresent:默认值,镜像在宿主机上不存在时才拉取
-
Always:每次创建 Pod 都会重新拉取一次镜像
-
Never: Pod 永远不会主动拉取这个镜像
如果拉取公开的镜像,直接按照上述示例即可,但要拉取私有的镜像,是必须认证镜像仓库才可以,即docker login,而在K8S集群中会有多个Node,显然这种方式是很不放方便的!为了解决这个问题,K8s 实现了自动拉取镜像的功能。 以secret方式保存到K8S中,然后传给kubelet。
apiVersion: v1
kind: Pod
metadata:
name: my-pod
spec:
imagePullSecrets:
- name: myregistrykey
containers:
- name: java
image: lizhenliang/java-demo
imagePullPolicy: IfNotPresent
上述中名为 myregistrykey 的secret是由kubectl create secret docker-registry命令创建:
kubectl create secret docker-registry myregistrykey --docker-username=admin --docker-password=Harbor12345 --docker-email=admin@harbor.com --docker-server=192.168.3.70
--docker-server: 指定docke仓库地址 --docker-username: 指定docker仓库账号 --docker-password: 指定docker仓库密码 --docker-email: 指定邮件地址(选填)
5.5 资源限制
Pod资源配额有两种:
- 申请配额:调度时使用,参考是否有节点满足该配置
spec.containers[].resources.limits.cpu
spec.containers[].resources.limits.memory
- 限制配额:容器能使用的最大配置
spec.containers[].resources.requests.cpu
spec.containers[].resources.requests.memory
示例:
apiVersion: v1
kind: Pod
metadata:
name: web
spec:
containers:
- name: java
image: lizhenliang/java-demo
resources:
requests:
memory: "64Mi"
cpu: "250m"
limits:
memory: "128Mi"
cpu: "500m"
其中cpu值比较抽象,可以这么理解:
1核=1000m
1.5核=1500m
那上面限制配置就是1核的二分之一(500m),即该容器最大使用半核CPU。
该值也可以写成浮点数,更容易理解:
半核=0.5
1核=1
1.5核=1.5
5.6 重启策略
apiVersion: v1
kind: Pod
metadata:
name: my-pod
spec:
containers:
- name: java
image: lizhenliang/java-demo
restartPolicy: Always
restartPolicy字段有三个可选值:
-
Always:当容器终止退出后,总是重启容器,默认策略。
-
OnFailure:当容器异常退出(退出状态码非0)时,才重启容器。适于job
-
Never:当容器终止退出,从不重启容器。适于job
5.7 健康检查
默认情况下,kubelet 根据容器状态作为健康依据,但不能容器中应用程序状态,例如程序假死。这就会导致无法提供服务,丢失流量。因此引入健康检查机制确保容器健康存活。
健康检查有两种类型:
- livenessProbe
如果检查失败,将杀死容器,根据Pod的restartPolicy来操作。
- readinessProbe
如果检查失败,Kubernetes会把Pod从service endpoints中剔除。
这两种类型支持三种检查方法:
Probe支持以下三种检查方法:
- httpGet
发送HTTP请求,返回200-400范围状态码为成功。
- exec
执行Shell命令返回状态码是0为成功。
- tcpSocket
发起TCP Socket建立成功。
示例:
apiVersion: v1
kind: Pod
metadata:
labels:
test: liveness
name: liveness-exec
spec:
containers:
- name: liveness
image: busybox
args:
- /bin/sh
- -c
- touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy; sleep 60
livenessProbe:
exec:
command:
- cat
- /tmp/healthy
initialDelaySeconds: 5
periodSeconds: 5
上述示例:启动容器第一件事创建文件,停止30s,删除该文件,再停止60s,确保容器还在运行中。
验证现象:容器启动正常,30s后异常,会restartPolicy策略自动重建,容器继续正常,反复现象。
5.8 调度策略
先看下创建一个Pod的工作流程: create pod -> apiserver -> write etcd -> scheduler -> bind pod to node -> write etcd -> kubelet( apiserver get pod) -> dcoekr api,create container -> apiserver -> update pod status to etcd -> kubectl get pods
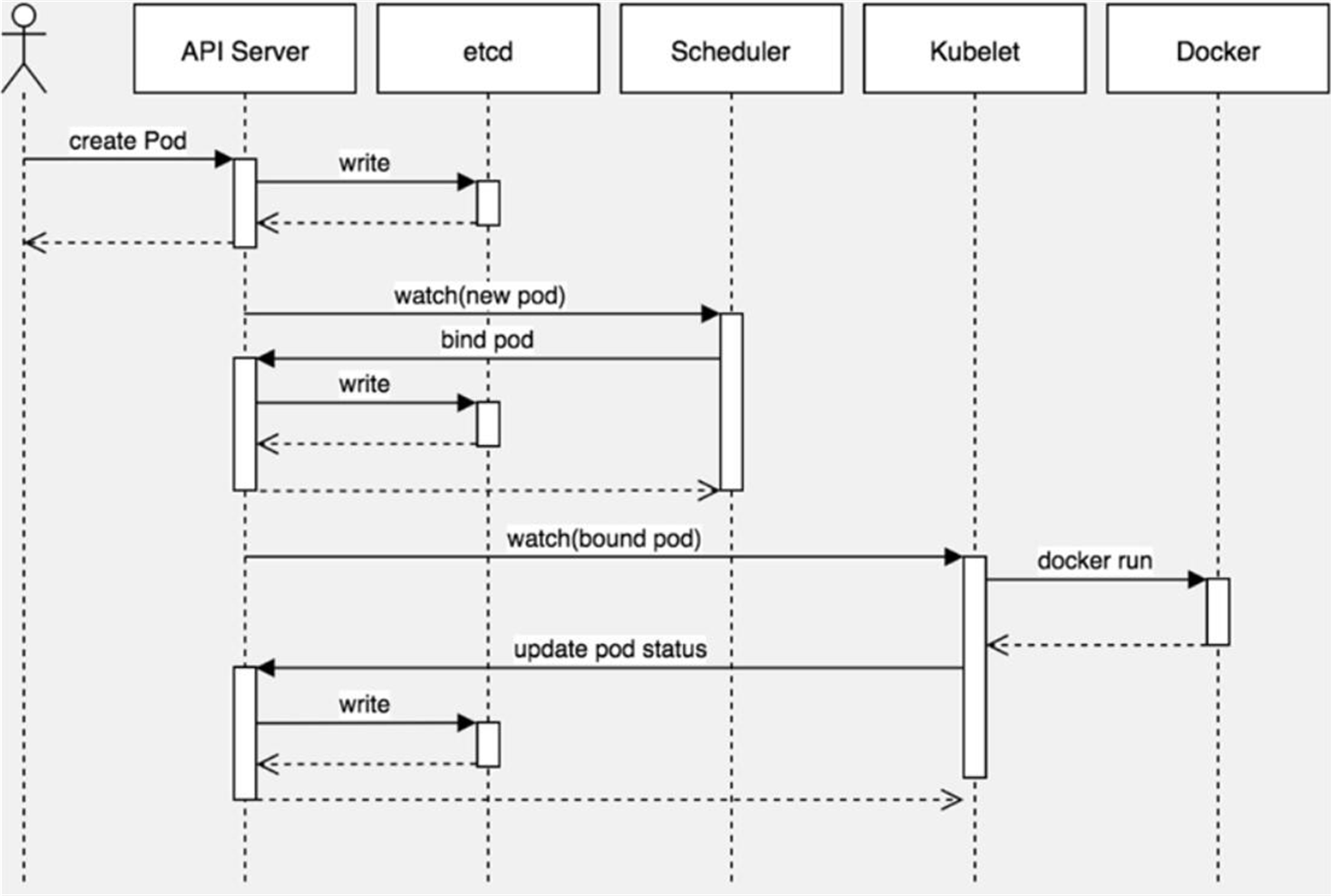
Pod根据调度器默认算法将Pod分配到合适的节点上,一般是比较空闲的节点。但有些情况我们希望将Pod分配到指定节点,该怎么做呢?
这里给你介绍调度策略:nodeName、nodeSelector和污点
1、nodeName
nodeName用于将Pod调度到指定的Node名称上。
例如:下面示例会绕过调度系统,直接分配到k8s-node1节点。
apiVersion: v1
kind: Pod
metadata:
labels:
run: busybox
name: busybox
namespace: default
spec:
nodeName: k8s-node1
containers:
- image: busybox
name: bs
command:
- "ping"
- "baidu.com"
2、nodeSelector
nodeSelector用于将Pod调度到匹配Label的Node上。
先给规划node用途,然后打标签,例如将两台node划分给不同团队使用:
kubectl label nodes k8s-node1 team=a
kubectl label nodes k8s-node2 team=b
然后在创建Pod只会被调度到含有team=a标签的节点上。
apiVersion: v1
kind: Pod
metadata:
name: busybox
namespace: default
spec:
nodeSelector:
team: b
containers:
- image: busybox
name: bs
command:
- "ping"
- "baidu.com"
3、taint(污点)与tolerations(容忍)
污点应用场景:节点独占,例如具有特殊硬件设备的节点,如GPU
设置污点命令:
kubectl taint node [node] key=value[effect]
其中[effect] 可取值:
-
NoSchedule :一定不能被调度。
-
PreferNoSchedule:尽量不要调度。
-
NoExecute:不仅不会调度,还会驱逐Node上已有的Pod。
示例:
先给节点设置污点,说明这个节点不是谁都可以调度过来的:
kubectl taint node k8s-node1 abc=123:NoSchedule
查看污点:
kubectl describe node k8s-node1 |grep Taints
然后在创建Pod只有声明了容忍污点(tolerations),才允许被调度到abc=123污点节点上。
apiVersion: v1
kind: Pod
metadata:
labels:
run: busybox
name: busybox3
namespace: default
spec:
tolerations:
- key: "abc"
operator: "Equal"
value: "123"
effect: "NoSchedule"
containers:
- image: busybox
name: bs
command:
- "ping"
- "baidu.com"
如果不配置容忍污点,则永远不会调度到k8s-node1。
去掉污点:
kubectl taint node [node] key:[effect]-
kubectl taint node k8s-node1 abc:NoSchedule-
5.9 故障排查
# 查看事件,可用于大部分资源
kubectl describe TYPE/NAME
# 如果pod启动失败,先查看日志
kubectl logs TYPE/NAME [-c CONTAINER]
# 进入到容器中debug
kubectl exec POD [-c CONTAINER] -- COMMAND [args...]